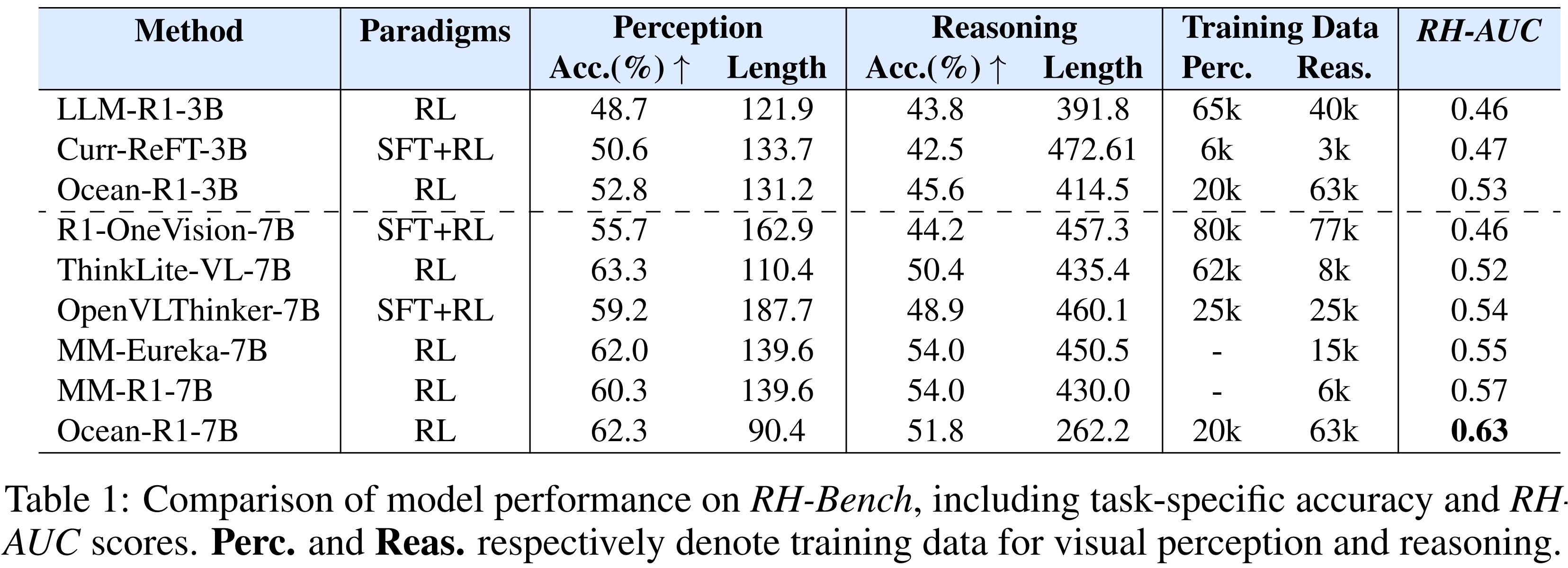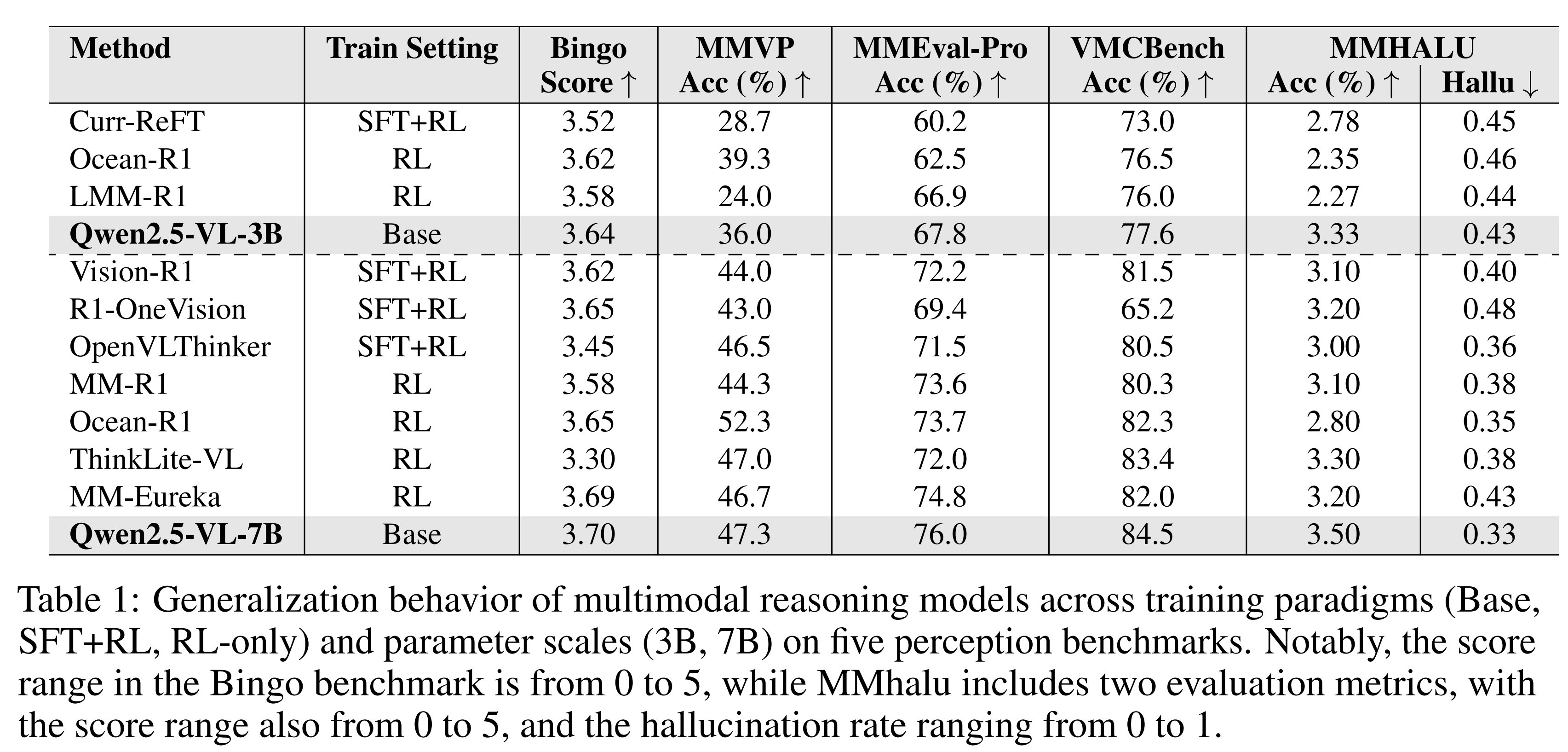
Test-time compute has empowered multimodal large language models to generate extended reasoning chains, yielding strong performance on tasks such as multimodal math reasoning. However, we observe that this improved reasoning ability often comes with increased hallucination: as generations become longer, models tend to drift away from image-grounded content and rely more on language priors. Attention analysis reveals that longer reasoning chains reduce focus on visual inputs, contributing to hallucination. To systematically study this phenomenon, we introduce RH-AUC, a metric that quantifies how a model's perception accuracy changes with reasoning length, enabling evaluation of whether the model preserves visual grounding while reasoning. We also release RH-Bench, a diagnostic benchmark covering diverse multimodal tasks, designed to jointly assess the balance of reasoning ability and hallucination. We find that (i) larger models generally exhibit a better balance between reasoning and perception; (ii) reasoning and perception balance depends more on the types and domains of the training data than its volume. Our findings highlight the need for evaluation frameworks that account for both reasoning quality and perceptual reliability.

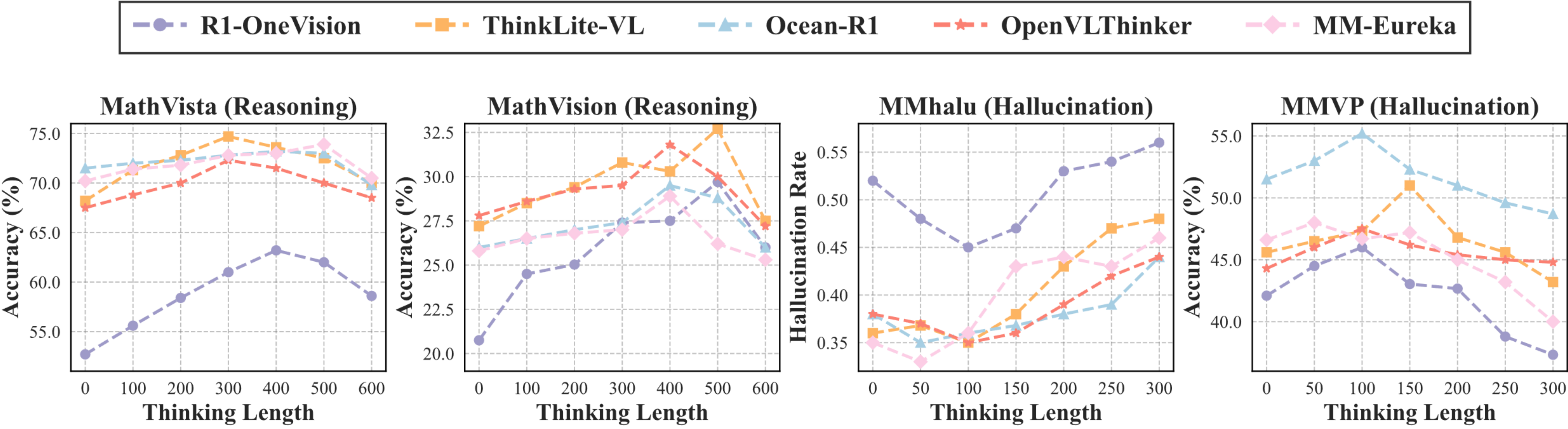
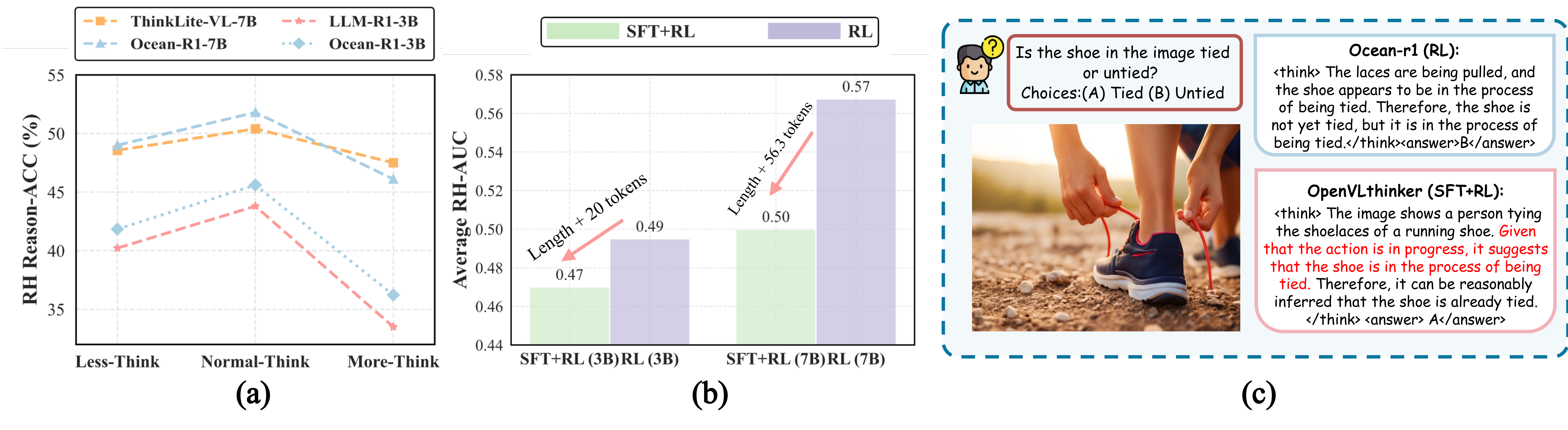
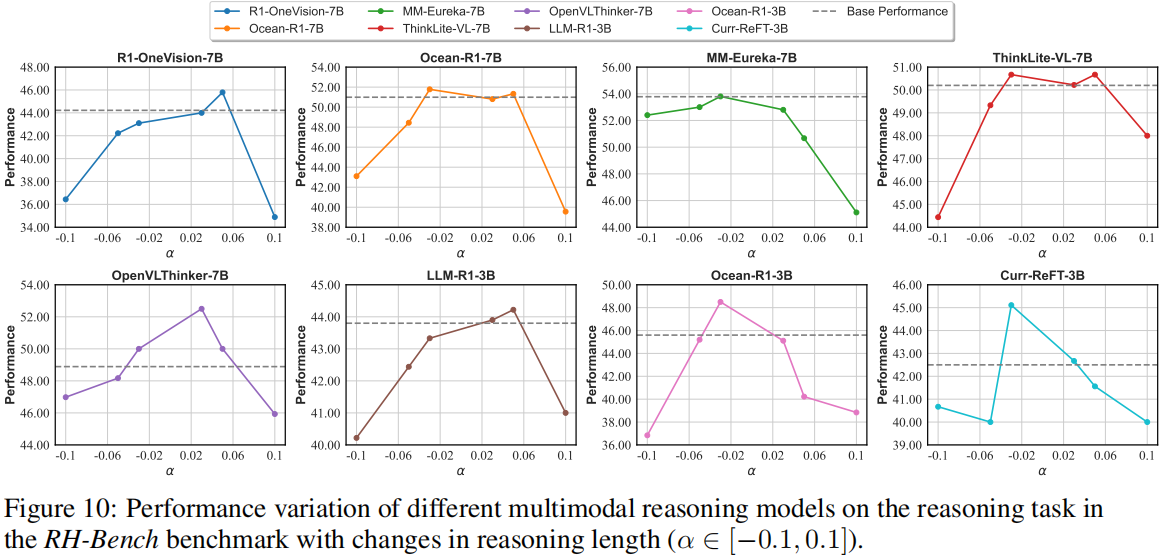
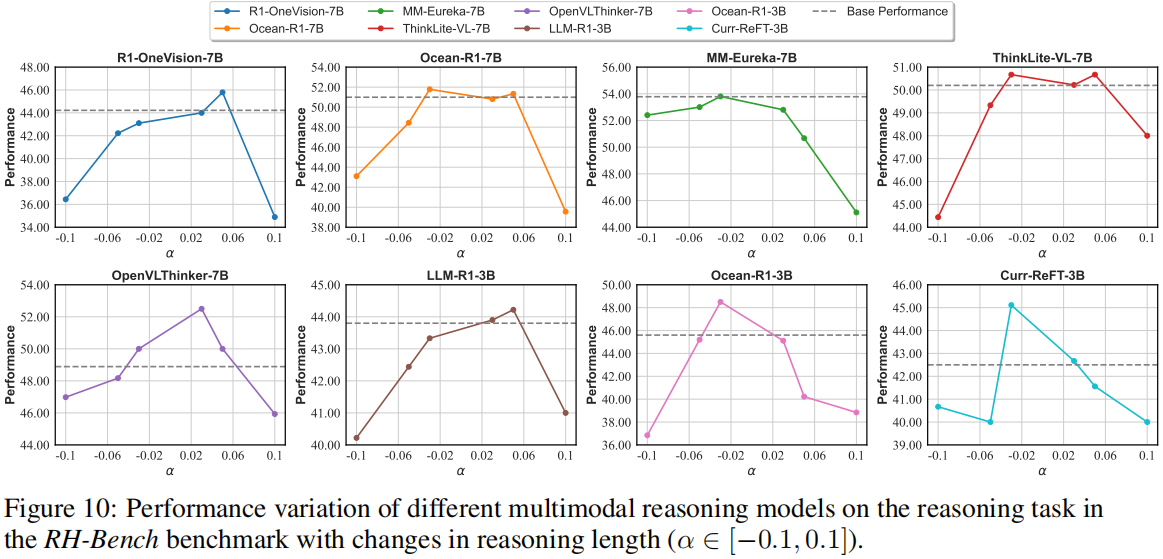
(a) Accuracy trends on the RH-Bench reasoning task across different reasoning lengths for 3B and 7B models. Larger models typically exhibit more stable performance across varying reasoning lengths. (b) Comparison of SFT+RL and RL-only training paradigms in terms of RH-AUC, with arrow directions indicating the increase in reasoning length for SFT+RL relative to RL-only. RL-only training tends to generate more concise reasoning chains, leading to a better perception hallucination balance. (c) Case study comparing RL-only and SFT+RL models. SFT+RL models often introduce rigid imitation reasoning paths, which limit the flexibility of visual reasoning.
@misc{liu2025thinkingseeingassessingamplified,
title={More Thinking, Less Seeing? Assessing Amplified Hallucination in Multimodal Reasoning Models},
author={Chengzhi Liu and Zhongxing Xu and Qingyue Wei and Juncheng Wu and James Zou and Xin Eric Wang and Yuyin Zhou and Sheng Liu},
year={2025},
eprint={2505.21523},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.21523},
}